In this section, we aim to analyze why and how the misaligned issue occurs, paving the way for the following sections about alignment techniques.
Overview of Failure Modes
We will give an overview of alignment failure modes, which can be categorized into reward hacking and goal misgeneralization.
Reward Hacking
In practice, proxy rewards are often accessible to optimize and measure. Yet, they frequently fall short of capturing the full spectrum of the actual rewards. The pursuit of optimization based on such rewards may lead to a phenomenon known as reward hacking, wherein agents may appear highly proficient according to specific metrics but fall short when evaluated against human standards.
Summarized by Alignment Survey Team. For more details, please refer to our paper.
For example, despite frequently catching fire, colliding with other boats, and going in the wrong direction, the agent achieves a higher score using this strategy.

OpenAI Research (Amodei et al., 2016)
Reward tampering can be considered a particular case of reward hacking, referring to AI systems corrupting the reward signals generation process. Everitt et al. delves into the subproblems encountered by RL agents:
- Tampering of reward function, where the agent inappropriately interferes with the reward function.
- Tampering of reward function input, which entails corruption within the process responsible for translating environmental states into inputs for the reward function.
When the reward function is formulated through feedback from human supervisors, models can directly influence the provision of feedback. Since task specification has its physical instantiation, the AI systems deployed in the real world have the potential to practice manipulation behaviors, resulting in more hazardous outcomes.
Goal Misgeneralization
Goal misgeneralization is another failure mode, wherein the agent actively pursues objectives distinct from the training objectives in deployment while retaining the capabilities it acquired during training.
For instance, in CoinRun games, the agent frequently prefers reaching the end of a level, often neglecting relocated coins during testing scenarios.

Goal Misgeneralization in Deep Reinforcement Learning (Langosco et al., 2022)
It should be noted that goal misgeneralization can occur in any learning system, not limited to RL, since the core feature is the pursuit of unintended goals. Moreover, it might be more dangerous if advanced AI systems escape our control and leverage their capabilities to navigate toward undesirable states.
Feedback-induced Misalignment
It’s worth noting that a substantial portion relies on feedback rewards derived from human advisors. We introduce the mechanism of Feedback-induced Misalignment. The issues are particularly pressing in open-ended scenarios, and we can attribute them to two primary factors.
Limitations of Human Feedback
During the training of large language models (LLMs), inconsistencies can arise from human data annotators. Moreover, they might even introduce biases deliberately, leading to untruthful preference data.
Training language models to follow instructions with human feedback (Ouyang et al., 2022)
Limitations of Reward Modeling
Training reward models using comparison feedback can pose significant challenges in accurately capturing human values. For example, these models may unconsciously learn suboptimal or incomplete objectives, resulting in reward hacking.
This example shows a robot arm was trained using human feedback to grab a ball but instead learned to place its hand between the ball and camera, making it falsely appear successful.
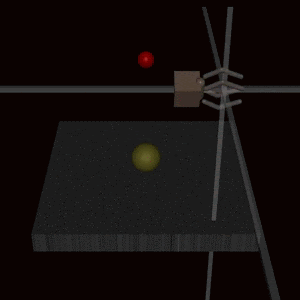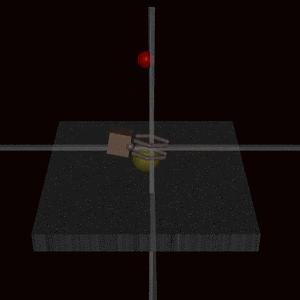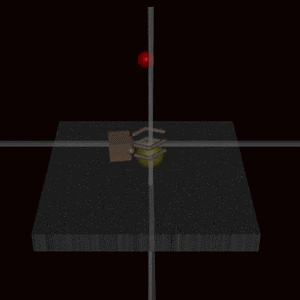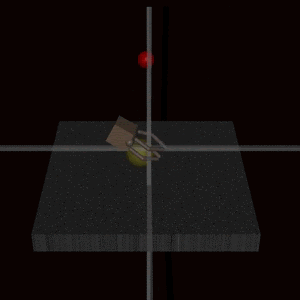
Deep Reinforcement Learning from Human Preferences (Christiano et al., 2017)
Meanwhile, using a single reward model may need help to capture and specify the values of a diverse human society.
Feedback-Induced Misalignment
While many current AI systems are primarily driven by self-supervision, it’s worth noting that a substantial portion relies on feedback rewards derived from human advisors, allowing us to introduce the mechanism of feedback-induced misalignment. The misalignment issues are particularly pressing in open-ended scenarios, and we can attribute them to two primary factors.
Defining and Characterizing Reward Hacking (Skalse et al., 2022)
Limitations of Human Feedback
During the training of LLMs, inconsistencies can arise from human data annotators. Moreover, they might even introduce biases deliberately, leading to untruthful preference data.
Limitations of Reward Modeling
Training reward models using comparison feedback can pose significant challenges in accurately capturing human values.
Misaligned Behaviors and Outcome
This section delves into a detailed exposition of specific misaligned behaviors(•) and introduces what we term double edge components(+). These components are designed to enhance the capability of AI systems in handling real-world settings but also potentially exacerbate misalignment issues.
With increased model scale, a class of dangerous capabilities(*) could also emerge. The dangerous capabilities(*) are concrete tasks the AI system could carry out; they may not necessarily be misaligned in themselves but are instrumental to actualizing extreme risks.
Below, we introduce the double edge components(+), misaligned behaviors(•), and dangerous capabilities(*), respectively.
Summarized by Alignment Survey Team. For more details, please refer to our paper.
+ Situational Awareness
AI systems may gain the ability to effectively acquire and use knowledge about its status, its position in the broader environment, its avenues for influencing this environment, and the potential reactions of the world (including humans) to its actions.
+ Broadly-Scoped Goals
Advanced AI systems are expected to develop objectives that span long timeframes, deal with complex tasks, and operate in open-ended settings. Engaging in broadly-scoped planning can empower AI systems to generalize better on the OOD settings and serve as valuable assistants in realms such as human healthcare. However, it can also bring about the risk of encouraging manipulating behaviors.
+ Mesa-Optimization Objectives
The learned policy may pursue inside objectives when the learned policy itself functions as an optimizer (i.e., mesa-optimizer). However, this optimizer’s objectives may not align with the objectives specified by the training signals, and optimization for these misaligned goals may lead to systems out of control.
+ Access to Increased Resources
Future AI systems may gain access to websites and engage in real-world actions, potentially yielding a more substantial impact on the world. They may disseminate false information, deceive users, disrupt network security, and, in more dire scenarios, be compromised by malicious actors for ill purposes. Moreover, their increased access to data and resources can facilitate self-proliferation, posing existential risks.
• Power-Seeking Behaviors
AI systems may exhibit behaviors that attempt to gain control over resources and humans and then exert that control to achieve its assigned goal. The intuitive reason why such behaviors may occur is the observation that for almost any optimization objective, the optimal policy to maximize that quantity would involve power-seeking behaviors, assuming the absence of solid safety and morality constraints.
• Measurement Tampering
Multiple model measurements can be manipulated by models, resulting in an illusion of favorable outcomes, even in cases where the desired objectives are not met. This deceptive practice can be seen as a specific kind of specification gaming, enabling models to escape detection techniques and presenting a false impression of alignment.
• Untruthful Output
AI systems such as LLMs can produce either unintentionally or deliberately inaccurate output. Such untruthful output may diverge from established resources or lack verifiability, commonly referred to as hallucination.
• Deceptive Alignment & Manipulation
Manipulation & Deceptive Alignment is a class of behaviors that exploit the incompetence of human evaluators or users and even manipulate the training process through gradient hacking or reward tampering.
• Collectively Harmful Behaviors
AI systems have the potential to take actions that are seemingly benign in isolation but become problematic in multi-agent or societal contexts.
• Violation of Ethics
Unethical behaviors in AI systems pertain to actions that counteract the common good or breach moral standards—such as those causing harm to others. These adverse behaviors often stem from omitting essential human values during the AI system’s design or introducing unsuitable or obsolete values into the system.
* Dangerous Capabilities
As AI systems are deployed in the real world, they may pose risks to society in many ways (e.g., hack computer systems, escape containment, and even violate ethics). They may hide unwanted behaviors, fool human supervisors, and seek more resources to become more powerful. Moreover, double edge components(+) may intensify the danger and lead to more hazardous outcomes, even resulting in existential risks.