TOP-10 Papers Recommended in 2024-02
| Papers | Authors | Published in | Date | |
|---|---|---|---|---|
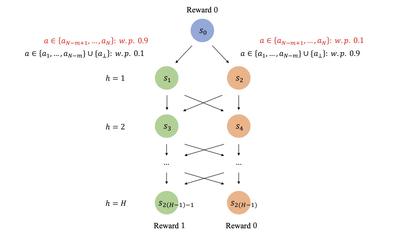
| Achieving Efficient Alignment through Weak-to-Strong Correction | Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Yaodong Yang | arXiv preprint | 2024-02 | |
| A Minimaximalist Approach to Reinforcement Learning from Human Feedback | Gokul Swamy, Christoph Dann, Rahul Kidambi, Zhiwei Steven Wu, Alekh Agarwal | arXiv preprint | 2024-01 | |
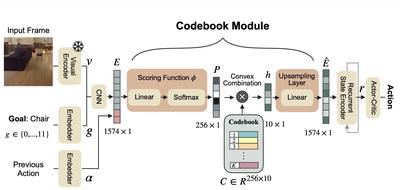
| Selective Visual Representations Improve Convergence and Generalization for Embodied AI | Ainaz Eftekhar, Kuo-Hao Zeng, Jiafei Duan, Ali Farhadi, Ani Kembhavi, Ranjay Krishna | International Conference on Learning Representations | 2023-11 | |
| Improving Generalization of Alignment with Human Preferences through Group Invariant Learning | Rui Zheng, Wei Shen, Yuan Hua, Wenbin Lai, Shihan Dou, Yuhao Zhou, Zhiheng Xi, Xiao Wang, Haoran Huang, Tao Gui, Qi Zhang, Xuanjing Huang | International Conference on Learning Representations | 2023-10 | |
| Confronting Reward Model Overoptimization with Constrained RLHF | Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, Stephen McAleer | International Conference on Learning Representations | 2023-10 | |
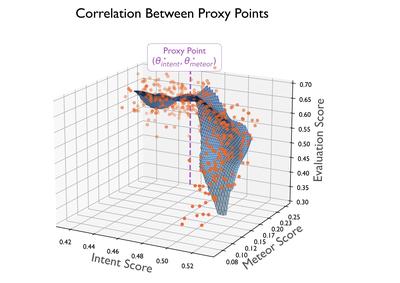
| Tool-Augmented Reward Modeling | Lei Li, Yekun Chai, Shuohuan Wang, Yu Sun, Hao Tian, Ningyu Zhang, Hua Wu | International Conference on Learning Representations | 2023-10 | |
| Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning | Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu | International Conference on Learning Representations | 2023-09 | |
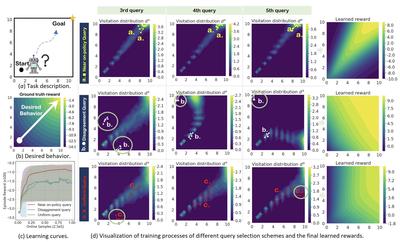
| Query-Policy Misalignment in Preference-Based Reinforcement Learning | Xiao Hu, Jianxiong Li, Xianyuan Zhan, Qing-Shan Jia, Ya-Qin Zhang | International Conference on Learning Representations | 2023-05 | |
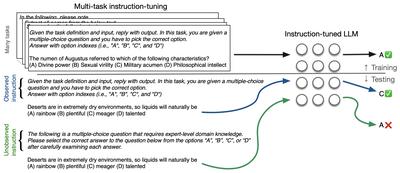
| Evaluating the Zero-shot Robustness of Instruction-tuned Language Models | Jiuding Sun, Chantal Shaib, Byron C. Wallace | International Conference on Learning Representations | 2023-06 | |
| Cascading Reinforcement Learning | Yihan Du, R. Srikant, Wei Chen | International Conference on Learning Representations | 2024-01 |
Authors: Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Yaodong Yang
Published in: arXiv preprint
Date: 2024-02
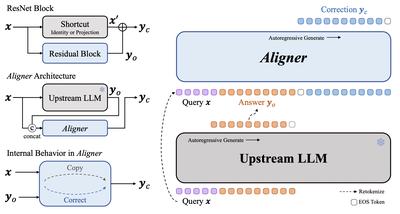
Authors: Gokul Swamy, Christoph Dann, Rahul Kidambi, Zhiwei Steven Wu, Alekh Agarwal
Published in: arXiv preprint
Date: 2024-01
Authors: Ainaz Eftekhar, Kuo-Hao Zeng, Jiafei Duan, Ali Farhadi, Ani Kembhavi, Ranjay Krishna
Published in: International Conference on Learning Representations
Date: 2023-11
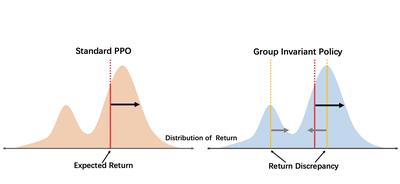
Authors: Rui Zheng, Wei Shen, Yuan Hua, Wenbin Lai, Shihan Dou, Yuhao Zhou, Zhiheng Xi, Xiao Wang, Haoran Huang, Tao Gui, Qi Zhang, Xuanjing Huang
Published in: International Conference on Learning Representations
Date: 2023-10
Authors: Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, Stephen McAleer
Published in: International Conference on Learning Representations
Date: 2023-10
Authors: Lei Li, Yekun Chai, Shuohuan Wang, Yu Sun, Hao Tian, Ningyu Zhang, Hua Wu
Published in: International Conference on Learning Representations
Date: 2023-10

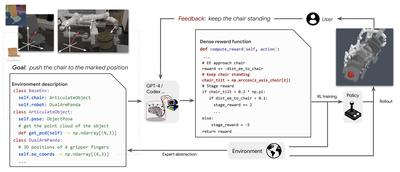
Authors: Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu
Published in: International Conference on Learning Representations
Date: 2023-09
Authors: Xiao Hu, Jianxiong Li, Xianyuan Zhan, Qing-Shan Jia, Ya-Qin Zhang
Published in: International Conference on Learning Representations
Date: 2023-05
Authors: Jiuding Sun, Chantal Shaib, Byron C. Wallace
Published in: International Conference on Learning Representations
Date: 2023-06
Authors: Yihan Du, R. Srikant, Wei Chen
Published in: International Conference on Learning Representations
Date: 2024-01